
اَلسَلامُ عَلَيْكُم
(Peace be upon you)
Building a Production GPU Dispatcher
Distributed GPU orchestration, job reliability, and the bugs we shipped.
↓
Select a theme for the best reading experience
February 2026 • ~15 min read
Update: The GPU Dispatcher's core patterns — lease-based locking, priority queuing, crash recovery via WAL — became the foundation of the Inference Gateway. The router was built on top of the dispatcher's architecture, extending it to orchestrate both external API providers and internal GPU infrastructure.
A thin orchestration layer that separates inference logic from infrastructure concerns. GPU engineers get a spec — implement POST /generate, GET /status/{id}, GET /health — and the dispatcher handles everything else: queuing, routing, retries, slot management, callbacks, crash recovery.
In practice this means a junior engineer can take the API spec, hand it to Claude Code, and have a working inference server scaffolded in an afternoon. They only need to understand the model they're serving — not the queue, not Redis, not retries, not slot management. That matters a lot when you're running a team that constantly experiments with and ships new models. The spec is the entire surface area they need to care about.
The second consequence: the dispatcher is compute-agnostic. Any server that speaks the spec is a valid backend — dedicated VMs, RunPod serverless, Salad, Lambda Labs. We run a fleet of dedicated H100s on Azure (fixed cost, 24/7) as our baseline, but serverless instances can be registered and deregistered dynamically. Burst capacity from RunPod or Salad slots in without code changes.
That reframes what the problem actually is. It's not just routing requests to GPU servers — it's building the layer that makes the underlying compute interchangeable and keeps the bar for adding a new model as low as possible.
Current setup:
Requirements: Zero job loss, FIFO ordering with priority support, efficient GPU utilization, handle crashes/restarts/network failures.
Replicate and Modal are the closest in terms of job model — async submission, polling, webhooks. The catch is straightforward: both are fully managed platforms. You push a Docker image, they run it on their hardware. Your dedicated H100s are irrelevant. These are for teams that don't own compute.
BentoML can actually deploy to your own VMs, so the hardware constraint goes away. The real issue is you'd need to rewrite your inference servers as BentoML services — their decorators, their runtime, their abstractions. It's not "implement this HTTP spec," it's "adopt our framework." Every GPU server becomes a BentoML service. A new engineer adding a model now needs to understand BentoML, not just the spec.
Ray Serve handles slot management, batching, and async inference well. But your GPU servers have to run as Ray deployments inside a Ray cluster. That means setting up Ray across your VMs, and every inference server gets rewritten against Ray's APIs instead of plain Python. Again — framework adoption, not a contract.
Triton Inference Server is solid if your models are standard formats — TensorRT, ONNX, TorchScript. But custom inference code doesn't fit: arbitrary Python preprocessing, multi-step pipelines, models with non-standard inputs. When you're adding new models regularly and a junior engineer is doing the implementation, Triton's model repository structure adds friction fast.
Celery + Redis is mechanically the closest. It gives you the queue primitives — workers pull tasks, execute them, retry on failure. But Celery has no concept of application-level slots (this specific GPU instance can handle exactly 4 concurrent jobs), no slot-aware routing, no async polling for long-running jobs, no WAL, no callbacks built in. You'd end up bolting all of that on yourself and writing the dispatcher anyway, just on top of Celery.
The gap across all of them: you either adopt a framework and rewrite your GPU servers, or you use a managed platform and give up your hardware. Nothing exposes a plain HTTP contract that any server can implement, on any compute, without framework buy-in. That's the space this sits in.
We needed reliable job delivery without adding infrastructure complexity.
Why not a load balancer? — The obvious first instinct. An LB routes requests to available backends and handles failover. But it assumes request-in, response-out. Our jobs run 21 seconds to 20 minutes. Each GPU has a hard slot limit (2–4 concurrent jobs). When all slots are full, an LB has one option: 503. It can't queue the work. It can't hold a connection for 20 minutes without timing out. It has no concept of application-level slots, no WAL, no retry semantics, no DLQ. Under any real burst, you'd be dropping jobs. You need something that absorbs the burst and drains it at the rate GPUs can actually handle.
Why not RabbitMQ/SQS? — Another service to operate, monitor, and scale. We already needed Redis for state management (locks, results, WAL). Adding a separate queue meant more moving parts.
Why Cloud Tasks? — Acts as a buffer between clients and our dispatcher. We can throw a million requests at it without overwhelming Azure App Service, which would straight up reject or lose requests if hit directly with that load. Cloud Tasks queues them and delivers at a controlled rate with built-in retries. No infrastructure to manage on our side — just HTTP endpoints.
Why Redis for queuing? — Already there for state. Sorted sets gave us exactly the priority logic and retry semantics we needed. Full control without fighting a framework.
A key design decision: GPU servers differentiate between dispatcher traffic and direct calls.
| Caller | Header | Behavior |
|---|---|---|
| Dispatcher | X-Source: dispatcher | Returns 503 if busy or if direct queue has pending jobs |
| Direct | None | Queued with priority (max 10), processed first |
Why this matters: When testing or running demos, direct API calls shouldn't compete with bulk dispatcher traffic. Direct calls go to a priority queue that drains completely before dispatcher traffic gets any slots.
@app.post("/generate")
def generate(request: Request, payload: GenerateRequest):
is_dispatcher = request.headers.get("X-Source") == "dispatcher"
if is_dispatcher:
# Reject if busy OR if direct queue has pending work
if len(active_jobs) >= MAX_CONCURRENT or len(direct_queue) > 0:
raise HTTPException(503, "GPU busy")
return process_job(payload)
else:
# Direct call - add to priority queue
if len(direct_queue) >= MAX_DIRECT_QUEUE:
raise HTTPException(503, "Queue full")
direct_queue.append(Job(id=job_id, payload=payload))
return {"status": "queued", "job_id": job_id, "position": len(direct_queue)}This creates a cooperative system: the dispatcher knows to route elsewhere on 503, and GPUs protect their capacity for high-priority direct access when needed.
Different models have different inference times. The dispatcher handles both patterns:
| Pattern | Inference Time | GPU Response | Dispatcher Behavior |
|---|---|---|---|
| Sync | < 30s | {"status": "success", "result": {...}} | Stores result immediately, releases lease |
| Async | > 30s | {"status": "processing", "job_id": "xxx"} | Spawns poller, holds lease until completion |
For async jobs, the dispatcher polls the GPU's /status/{job_id} endpoint every few seconds. The lease is held for the entire duration — not released after submission. This ensures the dispatcher's slot count matches actual GPU capacity.
# Model configuration determines behavior
"zimg": ModelConfig(
model_type=ModelType.SYNC, # Returns result immediately
)
"flux": ModelConfig(
model_type=ModelType.ASYNC,
poll_endpoint_template="/status/{id}",
poll_interval=3.0,
max_poll_time=1200.0, # 20 minutes max
)Instead of clients polling for results, they provide a callback_url:
POST /queue/submit
{
"model": "zimg",
"payload": {"prompt": "a sunset"},
"callback_url": "https://your-backend.com/webhook/gpu-result"
}When the job completes, dispatcher POSTs the result:
POST https://your-backend.com/webhook/gpu-result
{
"job_id": "job_123",
"status": "completed",
"result": {"url": "https://s3.../image.png"}
}Key point: The GPU never sees the client's callback_url. The dispatcher is always the intermediary:
callback_url, dispatcher stores it in job metadata/status endpoint (or GPU can call dispatcher's /tasks/callback/{job_id})callback_urlThe callback_url can be any endpoint — the original client, a different microservice, a Slack webhook, anything that accepts HTTP POST. The callback is fire-and-forget (with retries) after the slot is already freed for the next job.
┌─────────────┐
│ Client │
└──────┬──────┘
│ POST /queue/submit
▼
┌──────────────┐ creates task ┌─────────────────┐
│ Dispatcher │────────────────▶│ GCP Cloud Tasks │
└──────────────┘ └────────┬────────┘
▲ │
│ pushes task via HTTP │
└──────────────────────────────────┘
│
│ acquire lease, store state
▼
┌─────────────┐
│ Redis │
│ (Cluster) │
└─────────────┘
│
│ forward request
▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│ zimg │ │ flux │ │ trellis │
└─────────┘ └─────────┘ └─────────┘| Component | Role |
|---|---|
| Dispatcher | FastAPI service. Receives requests, manages GPU leases, routes to appropriate GPU |
| Redis Cluster | Stores locks, job queues, results, metadata. All state lives here |
| Cloud Tasks | Reliable task delivery with built-in concurrency control |
| GPU Services | Model-specific inference servers on Azure |
1. Client POSTs to /queue/submit
{"model": "zimg", "payload": {...}, "callback_url": "..."}
2. Dispatcher writes WAL entry
Redis: SET pending:job_abc {...} EX 86400
3. Dispatcher creates Cloud Task → gpu-zimg queue
4. Cloud Tasks calls /tasks/handle
5. Dispatcher acquires GPU lease
Redis: SET lock:zimg-api4-slot0 job_abc NX EX 300
6. Dispatcher POSTs to GPU
7. GPU returns response (sync or async job ID)
8. For async jobs: Dispatcher spawns poller
- Polls /status every 2-5 seconds
- Refreshes lease TTL every 60 seconds
9. On completion:
- Store result, release lease, send callback
- Delete WAL entry, trigger next job# GPU Instance Registry
models # SET: ["zimg", "flux", "trellis", ...]
model:{model}:instances # SET: ["zimg-api4-slot0", ...]
instance:{instance_id} # HASH: {endpoint, status, healthy}
# Atomic Locks (auto-expire)
lock:{instance_id} # STRING: job_id (EX: 300 seconds)
# Job Queue (sorted set = FIFO order)
jobs:queue:{model} # ZSET: {job_id: timestamp_score}
jobs:queue_data:{job_id} # HASH: {payload, callback_url, attempts}
# Results (with TTL)
result:{job_id} # JSON: {status, result, completed_at}
# Write-Ahead Log (crash recovery)
pending:{job_id} # JSON: {job_id, payload} (EX: 86400)
# Dead Letter Queue
jobs:dlq # LIST: [job_id, ...]Models and instances can be registered and configured at runtime — no redeployment needed.
Registering GPU Instances:
POST /admin/register
{
"model": "flux",
"server": "flux-server-1",
"endpoint": "https://flux.example.com/generate",
"slots": 2
}This automatically registers the instances in Redis and creates/updates the Cloud Tasks queue with correct concurrency limits.
Runtime Model Config:
Model behavior can be tuned via API without code changes:
# Get current config
GET /admin/model-configs/flux
# Update at runtime (stored in Redis, overrides code defaults)
PUT /admin/model-configs/flux
{
"model_type": "async",
"poll_endpoint_template": "/status/{id}",
"poll_interval": 5.0,
"max_poll_time": 1800,
"max_retries": 3
}
# Delete override (reverts to code default)
DELETE /admin/model-configs/fluxConfigurable Fields:
| Field | Description | Default |
|---|---|---|
model_type | "sync" or "async" | sync |
poll_endpoint_template | URL template for polling (e.g., "/status/{id}") | null |
id_field | Field name in GPU response containing job ID | null |
poll_interval | Seconds between poll requests | 2.0 |
max_poll_time | Max seconds to poll before timeout | 600 |
max_retries | Retries before moving to DLQ | 50 |
This lets you add new GPU models, adjust timeouts for slow models, or change retry behavior — all without touching code or restarting the dispatcher.
Core requirement: every submitted job must either complete or be explicitly marked as failed. No silent drops.
The pattern: write to durable storage before doing anything else.
async def submit_job(request: JobSubmitRequest) -> str:
job_id = generate_job_id()
# Step 1: Write to WAL FIRST
await redis.set(
f"pending:{job_id}",
json.dumps({...}),
ex=86400 # 24 hour TTL
)
# Step 2: Now create Cloud Task
await cloud_tasks.create_task(job_id, request)
return job_idA reconciler runs every 5 minutes, finds jobs in WAL for >5 min without completion, and re-queues them. WAL entry deleted only on definitive completion.
Redis sorted set for the queue. Score determines order:
async def add_to_queue(job_id, model, payload, priority=False):
if priority:
score = time.time() - 1e12 # Negative scores go first
else:
score = time.time()
await redis.zadd(f"jobs:queue:{model}", {job_id: score})Bug: Priority LIFO — First implementation used score = -timestamp. Newer priority jobs had more negative scores, so LIFO not FIFO. Fix: score = timestamp - 1e12
Failed jobs retry with increasing delays:
def calculate_retry_delay(attempt: int) -> float:
base_delay = 1.0
max_delay = 30.0
delay = min(base_delay * (2 ** attempt), max_delay)
# Add ±10% jitter to prevent thundering herd
jitter = delay * 0.1 * (random.random() * 2 - 1)
return delay + jitter
# Attempt 0: ~1s
# Attempt 1: ~2s
# Attempt 2: ~4s
# Attempt 3: ~8s
# Attempt 4: ~16s
# Attempt 5+: ~30s (capped)The jitter prevents multiple failed jobs from retrying at exactly the same time (thundering herd).
After 50 retries, jobs move to DLQ for manual inspection:
async def move_to_dlq(job_id: str, error: str):
job_data = await redis.hgetall(f"jobs:queue_data:{job_id}")
await redis.rpush("jobs:dlq", job_id)
await redis.hset(f"jobs:dlq_data:{job_id}", mapping={
**job_data,
"error": error,
"failed_at": datetime.utcnow().isoformat()
})
await update_result(job_id, status="max_retries_exceeded")Admin endpoints let you inspect DLQ, retry specific jobs, or retry all:
GET /admin/dlq # List all DLQ jobs
POST /admin/dlq/{job_id}/retry # Retry specific job
POST /admin/dlq/retry-all # Retry everything
DELETE /admin/dlq/{job_id} # Delete from DLQSometimes jobs get stuck — GPU accepts the request but never responds (process crash, OOM, infinite loop). A background worker runs every 60 seconds:
async def orphan_detector():
while True:
processing_jobs = await get_jobs_by_status("processing")
for job in processing_jobs:
started_at = parse_datetime(job["started_at"])
if now() - started_at > timedelta(minutes=10):
await update_result(job["job_id"],
status="failed",
error="Exceeded max processing time")
await release_lease(job["instance_id"])
await asyncio.sleep(60)Jobs stuck in "processing" for >10 minutes get marked failed and their lease released. The WAL reconciler can then pick them up for retry if attempts remain.
When a job completes, we immediately trigger the next one:
async def release_lease(instance_id: str, trigger_next: bool = True):
await redis.delete(f"lock:{instance_id}")
if trigger_next:
model = instance_id.split("-")[0]
asyncio.create_task(process_next_job(model))But we also run a background worker every 2 seconds that checks for available slots:
async def queue_worker():
while True:
for model in await get_all_models():
available_slots = await count_available_slots(model)
for _ in range(available_slots):
asyncio.create_task(process_next_job(model))
await asyncio.sleep(2)The event-driven path handles the normal case quickly. The polling fallback catches anything missed (network blip, dispatcher restart, race condition).
This is where subtle bugs live. Code that looked correct to me failed under concurrency, and multiple compute instances.
Each GPU slot protected by Redis lock:
async def acquire_lease(model: str, job_id: str) -> Optional[str]:
for instance_id in await get_instances(model):
# SET NX = only if not exists, EX = auto-expire
acquired = await redis.set(
f"lock:{instance_id}",
job_id,
nx=True,
ex=300
)
if acquired:
return instance_id
return NoneThe NX flag makes this atomic. Two dispatchers trying same slot = only one wins.
The loop above has a subtle issue: between checking instances and acquiring a lock, another dispatcher could grab it. For true atomicity, we use a Lua script that runs entirely within Redis:
-- Find a healthy instance and lock it in ONE atomic operation
local instances = redis.call('SMEMBERS', 'model:' .. model .. ':instances')
for _, instance_id in ipairs(instances) do
local healthy = redis.call('HGET', 'instance:' .. instance_id, 'healthy')
if healthy == 'true' then
-- SET NX = only set if not exists (atomic lock)
local acquired = redis.call('SET', 'lock:' .. instance_id, job_id, 'NX', 'EX', ttl)
if acquired then
return instance_id -- Got the lock!
end
end
end
return nil -- No available instanceThe entire script executes atomically — no other Redis commands can interleave. This eliminates race conditions between checking availability and acquiring the lock.
Lock TTL is 5 minutes (safety net if dispatcher crashes). But async jobs can take 20+ minutes. The poller refreshes the TTL every 60 seconds:
async def poll_async_job(job_id: str, instance_id: str):
try:
while True:
# Keep the lease alive
await redis.expire(f"lock:{instance_id}", 300)
status = await poll_gpu_status(job_id)
if status["status"] in ["success", "completed", "done"]:
return status["result"]
elif status["status"] in ["failed", "error"]:
raise GPUError(status.get("error"))
await asyncio.sleep(polling_interval)
finally:
# Always release, even on exception
await release_lease(instance_id)The try/finally ensures the lease is released even if the poller crashes or gets an unexpected exception.
Original code:
async def pop_next_job(model: str):
jobs = await redis.zrange(f"jobs:queue:{model}", 0, 0) # Get first
job_id = jobs[0]
await redis.zrem(f"jobs:queue:{model}", job_id) # Remove it
return await redis.hgetall(f"jobs:queue_data:{job_id}")The bug: zrange and zrem are separate commands. Not atomic. Concurrent workers could both get same job, one removes it, other gets stuck.
Fix: use ZPOPMIN which atomically pops and returns:
async def pop_next_job(model: str):
result = await redis.zpopmin(f"jobs:queue:{model}", count=1)
if not result:
return None
job_id = result[0][0]
return await redis.hgetall(f"jobs:queue_data:{job_id}")Original flow: pop job first, then try to acquire lease. If no capacity, put job back with incremented attempts.
async def process_next_job(model: str):
job = await pop_next_job(model) # Pop first
if not job:
return
instance_id = await acquire_lease(model, job["job_id"])
if not instance_id:
# No GPU slots available, put it back
await add_to_queue(job, increment_attempts=True) # BUG
return
await execute_job(job, instance_id)The bug: when no GPU capacity was available, we incremented the attempt count. Jobs burned through their retry budget just waiting for slots to free up.
Fix: acquire lease before popping:
async def process_next_job(model: str):
# Try to get a slot first
instance_id = await acquire_lease(model, "pending")
if not instance_id:
return # No capacity, leave jobs in queue untouched
# Now pop
job = await pop_next_job(model)
if not job:
await release_lease(instance_id)
return
# Update lock with actual job_id
await redis.set(f"lock:{instance_id}", job["job_id"], ex=300)
await execute_job(job, instance_id)Now retry count only increments on actual GPU failures, not capacity issues.
Distributed state can diverge from reality. The dispatcher's view (Redis locks) and the GPU's actual state can get out of sync in several scenarios:
Scenario 1: GPU Restart
GPU server restarts (deployment, crash, Azure maintenance). It comes back with 0 active jobs. But dispatcher still holds locks from before the restart — slots appear "busy" when they're actually free.
Scenario 2: Dispatcher Crash Mid-Job
Dispatcher crashes while a job is running on GPU. The lock has TTL so it will eventually expire. But the GPU might finish the job — result sits there with no one polling for it. The WAL reconciler handles job recovery, but locks need separate cleanup.
Scenario 3: Network Partition
Dispatcher loses connectivity to GPU mid-job. From dispatcher's view, job failed. From GPU's view, job completed successfully. Lock might get released (job "failed"), but GPU slot is still occupied until inference finishes.
The Solution: Lock Sync Worker
A background worker runs every 30 seconds, comparing dispatcher's lock state with GPU's reported state:
async def lock_sync_worker():
while True:
for server in await get_all_servers():
try:
health = await fetch_gpu_health(server)
if health["active_jobs"] == 0:
# GPU says it's idle, but we might have locks
locks = await get_locks_for_server(server)
for lock in locks:
ttl = await redis.ttl(f"lock:{lock}")
# Only clear old locks (TTL < 295 means lock is >5 sec old)
if ttl < 295:
await redis.delete(f"lock:{lock}")
logger.info(f"Cleared stale lock: {lock}")
except Exception as e:
logger.warning(f"Health check failed: {server}: {e}")
await asyncio.sleep(30)The TTL Check Race Condition
Why check ttl < 295? Consider this race:
The TTL check prevents this: fresh locks have TTL ~300. If TTL < 295, the lock is at least 5 seconds old — enough time for the job to show up in GPU's active_jobs count. We only clear locks that are definitively stale.
Why Not Just Use Lock TTL?
Lock TTL (5 min) is a safety net, not the primary mechanism. Without active sync:
In cluster mode, KEYS pattern only scans the node the client is connected to:
# This misses keys on other nodes!
keys = await redis.keys("result:*")Fix: iterate all nodes:
async def keys_all_nodes(self, pattern: str) -> list:
all_keys = []
if self.cluster_mode:
for node in self.redis.get_nodes():
node_client = self.redis.get_redis_connection(node)
keys = await node_client.keys(pattern)
all_keys.extend(keys)
else:
all_keys = await self.redis.keys(pattern)
return all_keys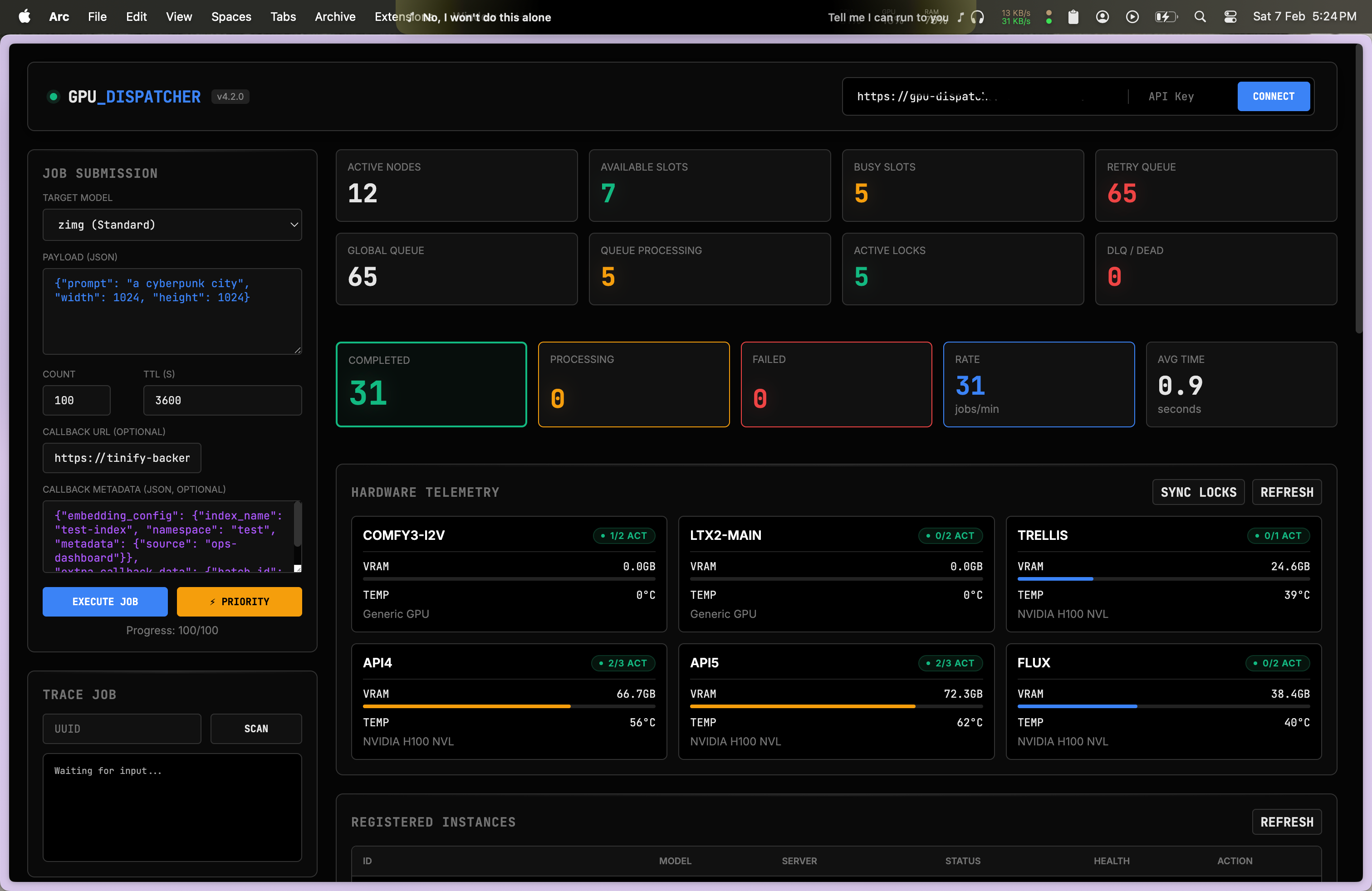
Load test with 50,000 jobs:
| Metric | Result |
|---|---|
| Completed + In Queue | ~49,500 (99%) |
| Lost | ~500 (1%) |
Throughput: ~18-22 jobs/min with 8 GPU slots.
Open Problem: Lost ~500 jobs to Azure App Service 502 errors during burst traffic. Job never enters system, WAL can't save it. Evaluating upstream queue buffer or horizontal scaling.
zrange + zrem looks atomic, isn't. Use ZPOPMIN.KEYS only hits one node. Iterate all nodes.-timestamp = LIFO. Use timestamp - 1e12 for priority FIFO.